
Through recent advancements in Artificial Intelligence, it is being more and more adopted into all areas of people’s lives and businesses, ranging from a farmer’s cucumber classification to automated fashion image tagging. One of the many benefits of AI is the possibility of picking up on more fine-grained patterns, which can help to give customers more personalized offers, predict when a machine needs maintenance, and find more nuanced anomalies in credit card usage.
What many of these areas have in common is that, from a technological point of view, they can use the same underlying methods to extract these patterns, called ‘clustering’ and combining clustering with AI has led to large improvements in the above-mentioned tasks. However, current AI-based clustering approaches face challenges when they’re being used on complex data (e.g. images) and developing solutions to this issue would have large practical implications as it could further propel AI’s capabilities in a variety of areas.
That’s why I decided to tackle these issues as part of my master’s project at BrainCreators. My goal is to better understand the black-box models used for deep-learning based clustering and to further improve it. In the upcoming series of blog posts, I will describe in detail how these techniques work and how I aim to improve them. The series will consist of three parts: In this first part, I will describe how clustering works and why it does not work well with large and complex datasets. In the second part, I will describe the deep learning techniques that can be used to perform clustering with large datasets and how I will improve it. In the third and last part, I will describe the results of my thesis and discuss how my improved could be applied to real-world applications.
Why Deep Learning for Clustering?
The first question one might ask is why deep learning may be useful here in the first place. To answer this question, I will briefly summarize the process of clustering and traditional ways of finding useful features in datasets and why these methods have difficulties performing well on large and complex datasets.
Imagine you have a dataset where every row is one data entry that represents either a cat or a dog. Every column represents a characteristic or feature (e.g. color, height, weight, claw type) of that animal. Your task is now to group the data entries so that, in the end, you’ll have two groups (or clusters), one with only dog entries and one with only cat entries. The only restriction is that you are not allowed to use the ‘Animal’ column because that’s the solution (or ground-truth) that we will later use to evaluate how good the clusters are.
Table 1: Animal attributes.
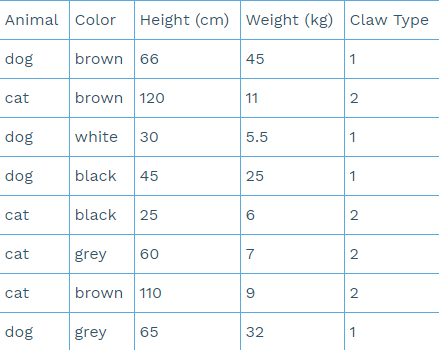
How would you go about doing that? As a first step, we would take two attributes, for example weight and height, and draw the data entries in a coordinate system (see Figure 1).

Now, to create two groups we need a way to calculate how different (or similar) each data point is to all others, and which combinations of data points will create the best clusters. To do this, we will follow a very popular method for clustering called the k-means clustering algorithm. This method is an iterative algorithm that consists of two steps: 1. cluster assignment, 2. centroid positioning.
Initially, the positions of the cluster centers are chosen randomly. Then, in the first step, the distance of every data entry to both clusters is calculated and the data entry is assigned to the closer cluster. Once all data entries are assigned, in step 2 the algorithm calculates the average position of all the points in the cluster and moves the centroid to that average location. Once that’s done, the new distances are calculated and points are assigned to the closer cluster and a new centroid position will be calculated. These two steps are repeated until the centroid positions stop changing. See Figure 2 for an example illustration with 3 clusters.

Figure 2. Source
In our example, the k-means clustering algorithm would create one cluster for two cat rows (#2 and #7) and a second cluster for the remaining data points. If we had a few more rows in the dataset, it would probably improve and yield a more accurate clustering result. Also, adding one or two more features (e.g. claw type) will significantly improve the clustering performance because additional features can give additional information about the underlying differences between the data points. Claw type, for example, has a perfect correlation with the ‘Animal’ column and could, therefore, largely improve the clustering accuracy.
Since adding more features in the above-mentioned example would lead to a better clustering performance, does it mean that additional features are always useful? In other words, could we collect thousands of features and just add everything into one big coordinate system to create perfect clusters? Although this sounds tempting, there are a couple of challenges that make this approach infeasible.

For example, let’s say we would like to cluster images based on the handwritten digits they show (see Figure 3). One 128×128 pixel image has a total of 16384 dimensions (one dimension per pixel) and, thus, we would have to calculate the distances between pixels in a 16384-dimensional coordinate system. Computationally, this is quite complex and would, therefore, take a long time. Additionally, we would just compare pixel values, which don’t say much about a digit. A handwritten 0 can look slightly different every time we write it and, accordingly, the pixels in the image would have different values every time. Still, the different variations would all represent a 0 (e.g. see first row in Figure 3).
At the same time, a 0 and a 6 could have very similar pixel values, even though they are actually different digits. This would lead to a big problem when using pixel distances for clustering because, in order to create good clusters, the average distance between the images in the same category (e.g. distances between handwritten 0’s) should be smaller than the average distance between images in different categories (e.g. average distance between a 0 and a 6). As the volume of a coordinate system grows exponentially with every added dimension, this issue grows bigger and bigger with every feature we add to the clustering technique, a phenomenon called the ‘curse of dimensionality’. It explains why clustering in a high-dimensional space does not work well.
Luckily, we do not need all dimensions to distinguish the digits from each other. There are many ways we could draw on a 128×128 image that would not represent any digit, which means that these combinations would never appear in the dataset. Thus, the amount of dimensions that we are actually interested in (i.e. relevant pixels) is usually much lower, and we can just do clustering on those relevant features.
Extracting relevant features
However, then the question becomes: “Which features are we interested in?” “What can we discard and what should we keep?” To answer these questions, mathematicians have developed procedures to extract the most relevant features or, to be exact, use transformations to create a new set that consists of fewer features and still captures the most important information of the original data. These methods are, for example, Principal Component Analysis (PCA), kernel methods and spectral methods. In many cases, using features extracted with these methods will strongly improve clustering performance.
Unfortunately, these traditional methods will not be sufficient when the underlying structure of the features is very complex. For example, if you want to capture the most relevant features of an object like a car or an airplane that is depicted in an image. In these scenarios, traditional methods will not be able to extract all relevant information, and that’s where deep learning comes in! Similar to the above-mentioned techniques, deep learning approaches also use transformations of the original set of features to create a new set that consists of fewer features but can still capture the most important information. However, deep learning’s advantage compared to traditional methods is that its transformations are highly non-linear, which is the reason why it can capture underlying structures that are more complex.
Now we know why deep learning can be helpful in clustering complex data. In the next part I will explain the deep learning techniques that can be used to perform clustering and how to further improve them.