
Andrej Karpathy is one of the few people in the AI world who has a deep understanding of the challenges of developing and maintaining a scalable and reliable AI solution for one of the most complex real world problems - autonomous driving. Tim Cook has been quoted saying that autonomous driving is "the mother of all AI projects”.
At Tesla Andrej is pushing the envelope of deep learning by combining multi-task learning and a massive "data engine" to collect rare examples that are the essence of addressing the long tail problem.
Earlier this year, in this talk at the CVPR Workshop of Scalability in Autonomous Driving, he summarizes the challenges Tesla and his team face and how they are tackling them. Most of what he discusses is already covered in previous talks, however if you are interested in autonomous driving and AI I strongly suggest that you watch it.
There's a lot to be learnt from Tesla's work in autonomous driving and AI in general. Below are the main points broken down for you:
- Why Tesla is relying on computer vision instead of LIDAR and HD maps
- The complexity of the long tail in data
- Operation vacation: how investing in a solid AI process allows you to iterate fast and reliably improve performance
- Tesla's data engine: the core of the process is to collect rare samples to address the long tail
- Tesla's data advantage: why is Tesla so efficient in collecting data
The first two points are mainly related to autonomous driving, and may be less relevant to your domain if you are not working in it, yet any company striving to benefit from adopting AI should strive to replicate Tesla's approach for points three to five. I'll circle back to this at the end of this post.

Relying on HD maps and LIDAR is not scalable
There are several reasons why exploiting high resolution maps and LIDAR is not scalable. From an algorithmic perspective, having access to a precise 3D point cloud of the environment that has been scanned in advance and LIDAR on the vehicle aiming to drive autonomously allows to localize a vehicle with a centimetre accuracy. That might sound like a solid approach, but what happens when the road configuration has changed between the time the scan was done and the car is driving at the location? This would require re-scanning each road periodically.
Furthermore, localization is only one of the challenges. From a perception point of view, recognizing other vehicles, pedestrians, and all other long tail situations (such as a flying chair lost from a truck) would in any case have to be addressed by analyzing images. Thus, starting from LIDAR only postpones tackling the bigger challenge.
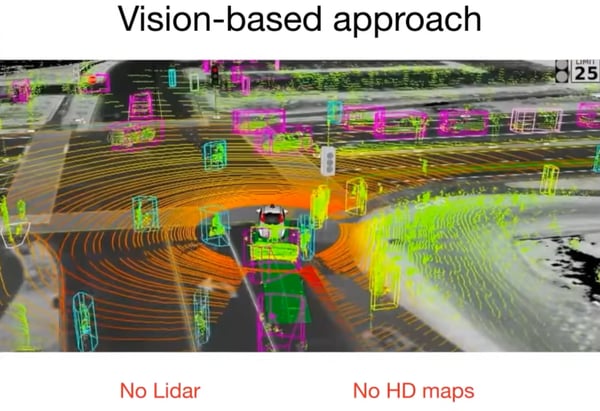
The real world is complex, diverse, evolving and long tailed
Full autonomous driving requires a long series of tasks including: accurately and reliably detecting the road and road markings, establishing the position of the vehicle on the road, detecting other vehicles, pedestrians and any other object on the road, and, last but not least, detecting traffic signs.
As an example, when thinking of detecting speed limits and stops signs, if your background is in machine learning your first intuition might be that modern Deep Neural Networks should be able to easily tackle the challenge. After all, traffic signs are rigid planar objects with convex shapes, no holes, standard shapes and designed to be high contrast and easily recognizable. This sounds like one of the easiest object detection tasks to solve.
Not so fast. The reality is as usual much harder. Two of the main challenges are:
- The taxonomy of traffic signs and their "modifiers" is vast and evolving. Each country adopts slightly different additions to traffics signs, modifications which are fundamental to correctly interpret how to safely drive without supervision. The taxonomy is also not fixed in time, as new variations are created over time and older ones discarded, yet potentially still present in a road somewhere on the planet. In the talk Andrej gives the example of speed limits.
- Even once such a taxonomy is known and maintained, the appearance of the traffic sign is highly varied, due to occlusions, lighting and the mere creativity of road maintenance companies in installing those signs. In the talk Andrej discusses this in relation to stop signs.

Here are four examples of the extremely long tail of cases fully autonomous driving vehicles would have to cope with: a chair flying off a pickup truck a dog running next to a car, a completely mirrored truck and cones laying on the street - which Andrej mentioned were recognized as red traffic lights.

Tesla summarized this in the following slide at Autonomy Day in April 2019.

Operation Vacation: Tesla's AI approach
In what Andrej defined already for some time as "Operation Vacation", he pushes his engineering team to focus on setting up the generic AI infrastructure to efficiently collect data, label it, train and reliably test models, so that the task of updating models to detect new objects can be handled by a separate product management and labeling team. This keeps the AI team at Tesla nimble and efficient - and jokingly at some point the team could be on vacation and the system would improve without any additional effort.
One of the fundamental requirements for this approach to work is the concept of data unit tests for the machine learning models: a set of examples on which models previously failed which need to be successfully passed. Performance on unit tests can never regress, only improvements are accepted for a new model to be released into production.

Tesla Data Engine
At the core of Operation Vacation is what Andrej calls Data Engine, shown below again from Andrej's presentation at Tesla Autonomy Day.
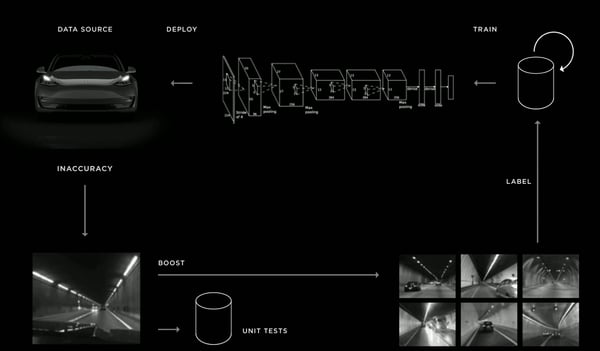
The goal of the Data Engine is to ensure data can be collected in the most efficient manner in order to cover the extremely long tail of examples required for models to reliably perform in the real unconstrained world. The core principle of the data engine is very simple:
- Label an initial dataset with new object classes
- Train models to detect new objects
- Evaluate performance
- Find cases in which performance is low
- Add those to the data unit test
- Deploy models to car fleet in shadow mode to fetch similar edge cases
- Retrieve cases from car fleet
- Review and label collected data
- Retrain models
- Repeat steps 6-9 until model performance is acceptable
We discussed the data unit test above, however steps 6 and 7 are equally important. Given the huge number of miles driven each day by Tesla vehicles - more on that in a second - how can the Data Engine ensure the labeling team won't be overwhelmed by false positives? Andrej mentions a few approaches in this talk, also admitting that no method works perfectly: flickering detection in the deployed model, neural network uncertainty from a Bayesian perspective, sudden appearance of a detection, discrepancy with an expected detection given map information.
Another approach which Tesla has been using to query potentially relevant examples is investigating all the autopilot disengagements: each time a Tesla driver whose vehicle is in autopilot mode decides to disengage autopilot, the likelihood of low performance in the model is high. The data engine can be used to fetch the most relevant examples out of all those cases too, allowing the labeling team to focus on the most critical improvements.
Below is an example of the type of data collected by the Data Engine after requesting to retrieve more stop signs obstructed by foliage.

To confirm the relevance of this approach to Tesla, Karphathy filed a patent application on this very subject.
Tesla's data advantage
The principle at the core of the Data Engine is not unique to Tesla: it is inspired by Active Learning and has been a hot research topic for years. The competitive advantage Tesla has is the unmatched scale of data collection.
Here is an estimation of Tesla Autopilot miles from Lex Fridman, which shows Tesla has collected more than 3 billion miles in autopilot. As a comparison, Google's Waymo recently announced it had collected 20 million miles since its inception in 2009. Tesla is currently leading by at least a factor 100.
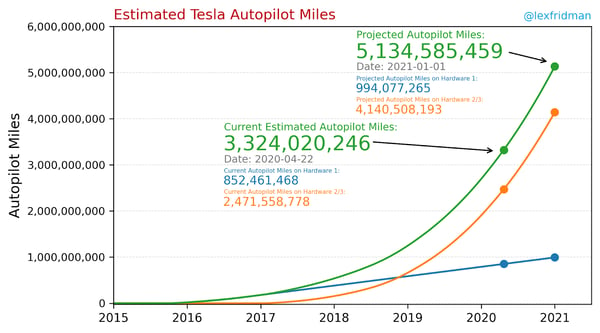
Not only is Tesla's current lead in the amount of data it has collected huge, the lead is likely going to expand at a faster rate. What's the reason for this? As George Hotz from Comma.ai very clearly discussed during this Tesla Third Row interview:
"If you want to add a new car to your network how much money does this cost? It costs Waymo more like you know 400.000$, it costs Comma negative 1.000$ and it costs Tesla negative 10.000$"
- George Hotz, Comma.ai -
Indeed Waymo's vehicles are very expensive due to the complex set of LIDAR sensors, and even more so, Waymo has to pay engineers to drive a vehicle as it is not yet allowed to let the vehicles drive without human supervision. Tesla on the other hand makes around 20% gross profit from each vehicle it sells, and consumers collect miles without Tesla having to pay them (obviously there are costs involved in the infrastructure Tesla needs to maintain to store, label and process data, but those are similar for any company working on autonomous driving).
Is this it?
So, is this all Tesla is doing in AI? Obviously not. There are lots of additional angles in which Tesla is pushing the current state of the art:
- Multi-task learning "HydraNet" training more than 50 models generating more than 1000 distinct predictions
- Learning to fuse the several camera inputs into a coherent Birds-Eye view, done through a Deep Neural Network
- Development of customer AI hardware: Full Self Driving Computers for inference in each car and "secret" DOJO training infrastructure

What can we all learn from it?
As promised at the beginning of the post, let's now look at what can be learnt from Tesla's approach to tackling autonomous driving. In particular I will look at the question from the angle of any company striving to be successful in applying AI.
- Invest in a solid AI process to collect data, label data, define data unit tests - reliable sets of data on which to test, train models and evaluate them. Do not underestimate the importance of the labeling step. Andrej says the following:
"The only sure certain way I have seen of making progress on any task is, you curate the dataset that is clean and varied and you grow it and you pay the labeling cost and I know that works."
- Create your Data Engine: most companies train a model until performance is good enough, and, if lucky enough to get there, deploy the model and forget about it. A much more reliable approach in the long term is to exploit models running in production to find the most critical data to update models with and at the same time to expand the set of data unit test.
- Strive to achieve a Data Advantage: it's no secret that collecting loads of relevant data is essential for success in AI. Designing a product/service from the ground up to be an efficient data collector is key, don't make it an afterthought. It's not always possible and easy - often due to privacy and other regulations - but often being transparent to the customer about which data will be collected and what the benefits. Even better aligning you and your customer's interest so that you both benefit from the data which is collected.
If you are interested in learning more about this approach and start applying it on your data, reach out to us at BrainCreators and let us show you how BrainMatter can help you.